개요
Enum을 Key로 사용하는 HashMap을 사용하고 있었다. 그러다 다른분들 코드를 보다가 Enum에 특화된 EnumMap 자료구조를 알게 됐다. 우선 내가 아는 정보는 다음과 같은데, Enum을 Key로 사용할때 HashMap대신 EnumMap을 사용한다면 성능상 이점이 있다는 정도이다. EnumMap의 자료구조 특성을 정리해봤다.
Chapter1. EnumMap 기본 이론
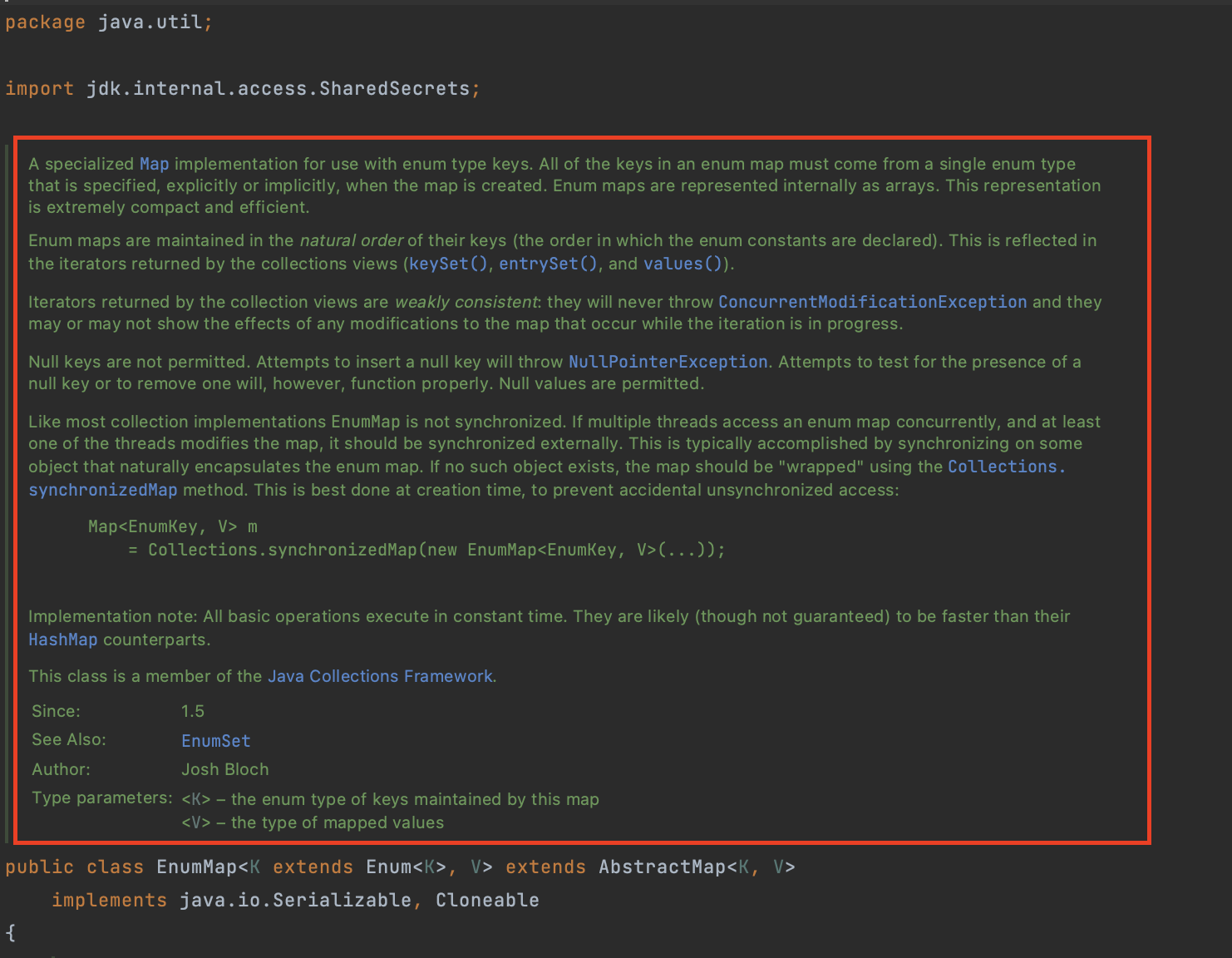
EnumMap의 JavaDoc 설명을 번역해서 정리한 내용은 다음과 같습니다.
1. Enum 타입 전용 Map
- EnumMap은 enum 타입 키 전용으로 최적화된 맵 구현체이다.
- 맵에 사용되는 모든 키는 하나의 enum 타입에서만 가져올 수 있다.
- 내부적으로 배열을 사용하므로 메모리 사용량이 작고 효율적이다.
2. 키의 정렬 및 반복자(Iterator)의 특성(weakly consistent)
- 키는 해당 enum이 선언된 순서(자연 순서)대로 정렬되어 관리된다.
- keySet(), entrySet(), values() 등으로부터 얻은 반복자(Iterator)는 weakly consistent 특성을 지닌다.
- 반복 중에 맵이 변경되어도 ConcurrentModificationException을 던지지 않는다.
- 변경 사항을 실제로 반영할 수도, 반영하지 않을 수도 있다.
3. Null 처리
- Null 키는 허용되지 않으며, 이를 삽입하려고 하면 NullPointerException이 발생한다.
- 단, Null 키가 존재하는지 확인(test)하거나 제거(remove)하려고 시도하는 것은 문제없이 동작하지만, 실제로 Null 키가 존재할 수 없으므로 특별한 효과는 없다.
- Null 값(value)은 사용 가능하다.
4. 동기화(Synchronization)
- 다른 컬렉션 구현체와 마찬가지로 EnumMap 자체는 스레드 안전하지 않다.
- 여러 스레드가 동시에 접근 및 수정하려면 외부에서 동기화가 필요하다.
- 일반적으로 Collections.synchronizedMap()을 사용해 동기화 래퍼(wrapper)를 만드는 방식이 권장된다.

5. 성능 특성
- 기본 연산들은 상수 시간(O(1))에 실행된다.
- 구현에 따라 HashMap보다 더 빠른 동작을 기대할 수 있지만, 이는 보장되지 않는다.
6. 자바 컬렉션 프레임워크의 일부이며, 자바 1.5부터 제공된다.
- 작성자는 Josh Bloch이며, EnumSet과 관련되어 있다.
# 정리
정리하자면, EnumMap은 특정 enum 타입을 키로 사용하는 경우에 매우 유용한, 가볍고 빠른 맵이다. 그러나 스레드 안전성이 보장되지 않으므로 멀티스레드 환경에서는 동기화 처리가 필수적이며, Null 키를 사용할 수 없다는 점에 주의해야 한다.
Chapter2. EnumMap 클래스 구조
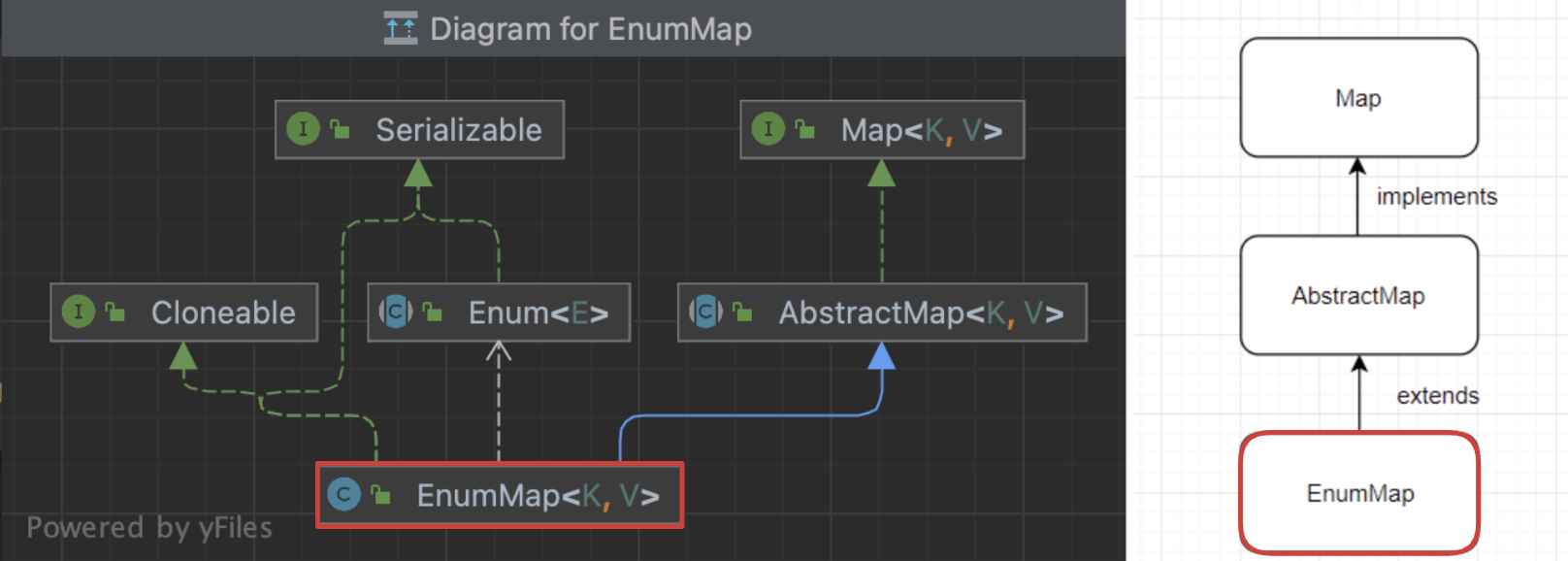
아래는 EnumMap의 선언부입니다. 보시다시피 HashMap과 마찬가지로 AbstractMap 클래스를 상속받고 있습니다. 다만, HashMap과 달리 Map 인터페이스를 직접 명시하여 implements하지는 않습니다.
왜냐하면 AbstractMap 자체가 이미 Map 인터페이스를 구현하고 있고, EnumMap은 그 기능을 확장해 사용하는 구조이기 때문입니다.
// HashMap의 선언부
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// 구현 내용
}
// EnumMap의 선언부
public class EnumMap<K extends Enum<K>, V> extends AbstractMap<K,V>
implements Cloneable, Serializable {
// 구현 내용
}여기서 볼 수 있듯이:
- HashMap은 Map 인터페이스를 명시적으로 implements 합니다
- EnumMap은 Map 인터페이스를 직접 implements 하지 않습니다
- 두 클래스 모두 AbstractMap을 상속받고, Cloneable과 Serializable을 구현합니다
- EnumMap은 타입 파라미터 K가 Enum 타입으로 제한됩니다 (<K extends Enum<K>)
AbstractMap이 이미 Map 인터페이스를 구현하고 있기 때문에 EnumMap이 다시 Map을 implements 할 필요가 없다는 것을 코드로 보여줍니다.
Q. EnumMap이 Map 인터페이스를 직접 구현하지 않는 이유가 궁금하다. (HashMap은 직접 구현하던데..)
공식 JavaDoc(EnumMap, AbstractMap) 어디에도 “왜 Map을 명시적으로 구현하지 않는가?”에 대한 구체적인 설명은 없었다.
하지만 Oracle Java 문서 EnumMap에 따르면, EnumMap이 AbstractMap의 하위 클래스이며, Map 인터페이스의 일부 기능을 재정의해 사용한다는 점은 명시되어 있다. "왜 굳이 Map을 재차 implements하지 않았는지" 에 대한 공식적인 ‘사유’는 없지만, EnumMap은 AbstractMap의 기능을 그대로 활용하면서, Enum 타입에 특화된 최적화만 추가하는 구조라는 특수화된 타입 제한을 의도적으로 드러내기 위해서라고 짐작해본다.
Chapter3. EnumMap 내부 구조
1. 상태필드
EnumMap은 기본적으로 keyType, keyUniverse,vals를 기본 필드로 가지고 있고, 생성 시점에 초기화가 진행된다.
각 필드들은 왜 존재하는 것일까?
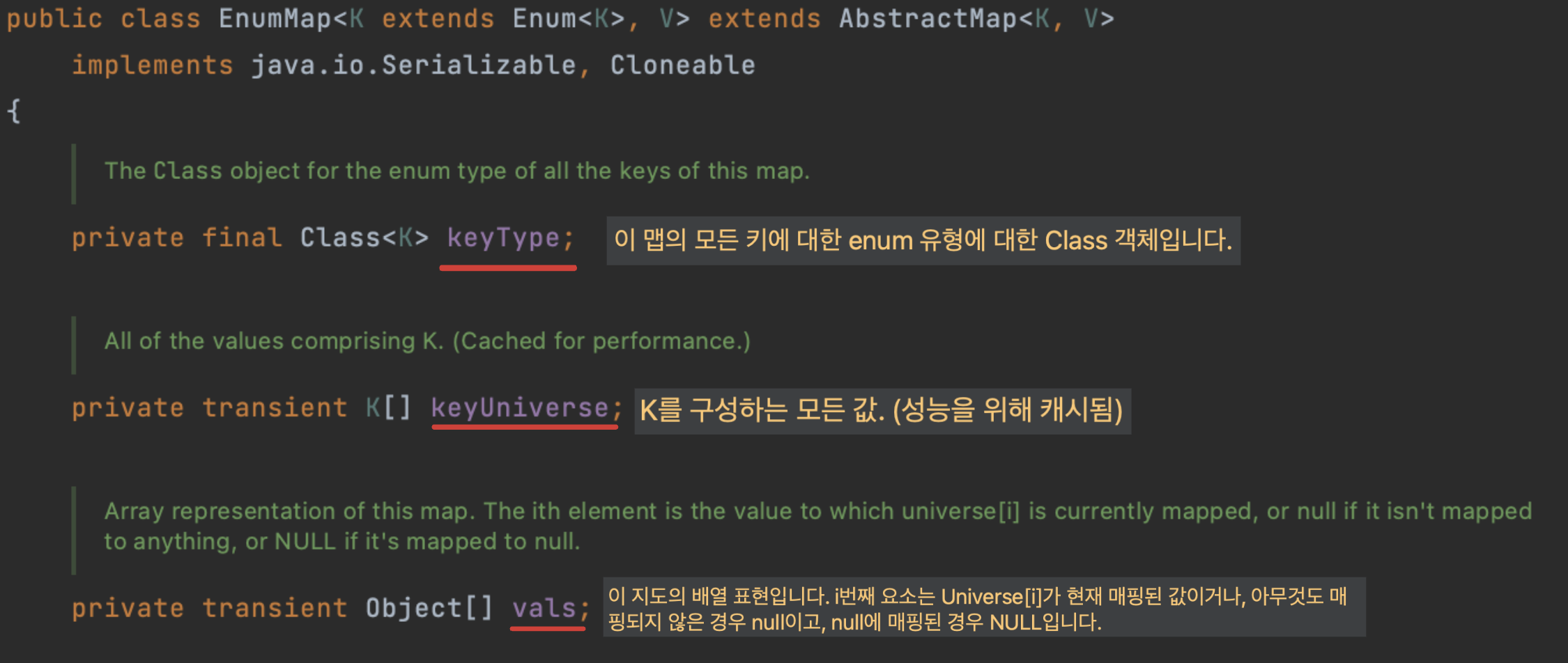

EnumMap의 주요 필드인 keyType, keyUniverse, vals는 각각 다음과 같은 목적을 가지고 존재합니다 :
private final Class<K> keyType
- 의미: 맵에서 사용될 enum 타입의 Class 객체
- 이유:
- EnumMap은 특정 enum 타입에 대해서만 Key를 허용하기 때문에, 생성 시점에 해당 enum 클래스 정보를 반드시 알아야 합니다.
- 내부적으로 그 타입의 정보(예: 제네릭 타입 추론, 직렬화 시 필요한 타입 정보 등)를 활용하기 위해 keyType 필드를 유지합니다.
private final Enum<?>[] keyUniverse
- 의미: EnumMap이 사용하는 키 enum의 모든 상수를 담고 있는 배열
- 이유:
- EnumMap은 내부적으로 enum의 ordinal 값을 활용해 값을 저장합니다.
- 따라서 enum이 가질 수 있는 모든 상수를 배열 형태로 미리 확보해 놓고, 인덱스를 통한 빠른 접근(상수의 ordinal → 배열 인덱스)을 가능케 합니다.
- 이 배열은 enum의 상수 선언 순서에 맞춰(정렬) 고정된 크기로 유지되므로, Null key를 허용하지 않고 효율적으로 맵을 구성할 수 있습니다.
private Object[] vals
- 의미: 실제로 값(value)들을 저장하는 배열
- 이유:
- EnumMap은 keyUniverse에 매핑되는 실제 값들을 vals 배열에 저장합니다.
- 예를 들어, vals[i]는 keyUniverse[i]에 해당하는 enum 상수의 매핑된 값이 됩니다.
- 이를 통해 상수 시간(O(1)) 접근이 가능하도록 설계되었고, Hash 기반이 아니라 배열 인덱스를 사용하는 방식이라 메모리 및 성능 면에서 효율적입니다.
# 정리
keyType: 사용될 enum의 타입 정보를 담는다.
keyUniverse: 열쇠(키) 후보 전체 , 모든 enum 상수를 배열 형태로 갖고 있어, 해당 상수들의 index를 관리한다.
vals:그 열쇠들에 대응하는 실제 값들 , keyUniverse 배열 상 각 enum 상수에 대응하는 값들을 저장한다.
이러한 구조 덕분에 EnumMap은 enum 키에 대해 빠른 조회와 적은 메모리 사용량을 제공하며, ordinal을 통해 직접 배열 인덱싱하는 최적화가 가능해집니다.
2. 생성자
JavaDoc Summary


요약본을 봤을 때, 설명을 봐서는 아직 감이 안잡히지만 인자들을 보면 내용을 유추할 수 있다.
1. EnumMap(Class<K> keyType)은 Enum 클래스 타입을 인자로해서 생성한다.
2. EnumMap(EnumMap<K, ? extends V> m)은 인자로 받은 EnumMap을 copy해서 생성하는 것 같다.
3. EnumMap(Map<K, ? extends V> m)은 인자로 받은 Map 자료구조를 EnumMap으로 변환해서 생성해주는 것 같다.
코드를 통한 확인
1. EnumMap(Class<K> keyType)

생성 코드
// enum 타입 클래스로 직접 생성
// DayOfWeek.class에는 월,화,수,목,금,토,일 상수를 가지고 있음
EnumMap<DayOfWeek, String> map1 = new EnumMap<>(DayOfWeek.class);매개변수
- keyType: EnumMap이 사용할 enum의 클래스 타입. (예: DayOfWeek.class)
초기화 과정
- this.keyType = keyType
- 매개변수로 받은 keyType을 EnumMap의 필드에 그대로 저장합니다.
- 이를 통해 이 EnumMap 객체가 어떤 enum 타입을 키로 사용할지 결정됩니다.
- keyUniverse = getKeyUniverse(keyType)
- 내부적으로 getKeyUniverse(...)를 호출하여,
- 해당 enum의 모든 상수(예: 월, 화, 수, 목, 금, 토, 일)를 배열(Enum<?>[]) 형태로 얻어옵니다.
- 이렇게 얻은 배열을 keyUniverse 필드에 저장합니다.
- 즉, “이 EnumMap이 다룰 수 있는 키 후보 전체”를 확보하는 단계입니다.
- vals = new Object[keyUniverse.length]
- keyUniverse.length만큼 Object[] 배열을 만들어 vals 필드에 할당합니다.
- 이후 (키, 값) 매핑을 넣게 될 때, keyUniverse[i](= i번째 enum 상수)에 매핑되는 실제 값은 vals[i]에 저장됩니다.
- 즉, (키, 값) 쌍을 동일한 인덱스로 연결시키는 구조를 만든 것입니다.
내부 상태 필드 요약
- keyType: “어떤 enum 타입을 다룰 것인지”에 대한 정보
- keyUniverse: “해당 enum의 모든 상수 목록” (배열)
- vals: “상수에 대응하는 값들을 담을 배열” (초기에는 null로 채워진 상태)
- size: 명시되어 있지 않지만, 별도 필드이며 기본값 0으로 초기화되어 있을 겁니다. (값이 아직 아무것도 들어있지 않으므로)
Q. getKeyUniverse()는 어떻게 동작하는 걸까?
getKeyUniverse(keyType) 메서드는 "해당 enum 타입이 가질 수 있는 모든 상수를 배열 형태로 얻어오는 기능"을 담당합니다. EnumMap에서 가장 중요한 점은, 키가 되는 enum 상수들을 배열 인덱스로 직접 사용한다는 것입니다.
예시)
1. DayOfWeek.MONDAY의 ordinal()이 0, TUESDAY가 1, …
2. 이런 식으로 ordinal(순번)을 배열 인덱스로 매핑해야 하기 때문에, 모든 상수를 미리 확보해둬야 합니다.
아래는 OpenJDK 21 기준의 EnumMap 소스에서 확인할 수 있는 getKeyUniverse 관련 코드입니다:

SharedSecrets.getJavaLangAccess()
- OpenJDK 내부에는 jdk.internal.access 클래스가 있습니다.
- SharedSecrets 클래스는 JDK 내부에서만 사용되는 비공개 API 이고, 보안에 민감한 작업이나 내부 리소스 접근을 위해 사용됩니다.
- getJavaLangAccess()는 java.lang 패키지의 내부 구현에 접근하기 위한 메서드입니다.
getEnumConstantsShared(keyType)
- SharedSecrets.getJavaLangAccess()가 반환하는 객체(JavaLangAccess 인터페이스)는 getEnumConstantsShared(Class<?>) 같은 메서드를 제공합니다.
- getEnumConstantsShared() 메서드는 keyType가 가진 모든 enum 상수를 '공유 배열' 형태로 반환합니다. 즉, keyType.getEnumConstants()와 유사하지만, 내부적으로 캐싱된 배열을 반환하여 성능 및 메모리 사용량을 최적화합니다. 그리고 공유 배열(shared)을 사용하므로, 매번 새 배열을 만드는 대신 동일한 배열 인스턴스를 재사용한다는 점이 특징입니다.
# 정리
getKeyUniverse는 EnumMap이 키로 사용되는 enum 상수를 전부 배열로 받아오기 위한 도우미 메서드다.
실제 구현에서 OpenJDK 내부 비공개 API(SharedSecrets)를 통해, 캐시된 enum 상수 배열을 얻어온다.
덕분에 EnumMap은 별도의 해싱 절차 없이 ordinal(순번) → 배열 인덱스 직접 매핑을 써서 빠르고 메모리 효율적인 동작을 할 수 있다.
getKeyUniverse() 자체가 성능을 높이는 직접적인 이유라기보다는 enum 상수를 미리 배열로 확보해 두고, 해시 연산 대신 해당 배열 인덱스를 사용해 (키, 값) 매핑을 관리하기 위한 준비 과정인 셈이다.
2. EnumMap(EnumMap<K, ? extends V> m) {

생성 코드
// 1. enum 타입 클래스로 직접 생성
EnumMap<DayOfWeek, String> map1 = new EnumMap<>(DayOfWeek.class);
// 2. 기존 EnumMap 복제
EnumMap<DayOfWeek, String> map2 = new EnumMap<>(map1);매개변수
- m: 이미 존재하는 동일한 키 타입의 EnumMap 객체
초기화 과정
- keyType = m.keyType
- 복사 대상인 EnumMap의 keyType을 그대로 가져옵니다.
- 즉, 동일한 enum 타입을 사용하는 EnumMap이 만들어집니다.
- keyUniverse = m.keyUniverse
- 복사 대상 m이 사용 중이던 enum 상수 배열(keyUniverse) 참조를 그대로 사용합니다.
- (enum의 모든 상수 목록은 어차피 동일하므로, 같은 배열을 가리켜도 문제없습니다.)
- vals = m.vals.clone()
- 복사 대상 m의 vals 배열을 복제(shallow copy)합니다.
- 즉, 새로운 배열을 만들어서 m.vals의 내용을 그대로 복사해옵니다.
- 이렇게 함으로써, 기존 m과는 독립적으로 값을 수정할 수 있는 상태가 됩니다.
- size = m.size
- 복사 대상 m의 현재 size(매핑된 (키, 값) 쌍의 개수)를 동일하게 가져옵니다.
내부 상태 필드 요약
- keyType: 복사된 EnumMap과 동일한 enum 타입
- keyUniverse: 복사된 EnumMap과 동일한 enum 상수 배열 (참조 공유)
- vals: 복사된 EnumMap의 값 배열을 clone해서 가짐 (실제 객체는 새 배열)
- size: 복사된 EnumMap의 (키, 값) 개수
3. EnumMap(Map<K, ? extends V> m)

이 생성자는 좀 더 범용적인 Map 인터페이스를 받아서 EnumMap을 초기화하는 방법을 제공합니다.
생성 코드
// 다른 Map (예: HashMap 등)으로부터 생성
Map<DayOfWeek, String> someMap = new HashMap<>();
someMap.put(DayOfWeek.MONDAY, "월요일");
someMap.put(DayOfWeek.TUESDAY, "화요일");
EnumMap<DayOfWeek, String> map3 = new EnumMap<>(someMap);
초기화 과정 (분기)
( If ) - m이 EnumMap의 인스턴스인 경우
사실상 EnumMap(EnumMap<K, ? extends V> m) 생성자와 같은 과정을 밟습니다.
- 캐스팅
- EnumMap<K, ? extends V> em = (EnumMap<K, ? extends V>) m;
- keyType = em.keyType;
- em의 키 타입 그대로 복사
- keyUniverse = em.keyUniverse;
- em이 사용 중이던 enum 상수 배열을 그대로 참조
- vals = em.vals.clone();
- 값 배열을 복제하여 독립적인 상태를 확보
- size = em.size;
- (키, 값) 쌍의 개수도 동일하게 설정
( else ) - m이 일반적인 Map이고, EnumMap이 아닌 경우
- 비어있는지 확인:
- 만약 m.isEmpty()라면 IllegalArgumentException 예외 발생
- 이유: 어떤 enum 타입으로 초기화해야 할지 알 수 없기 때문입니다. (첫 번째 키를 봐야 알 수 있으니까요)
- keyType = m.keySet().iterator().next().getDeclaringClass();
- m에서 첫 번째 키를 꺼내, 그 키가 속해있는 enum 클래스 정보를 얻습니다. (.getDeclaringClass())
- 이렇게 해서 어떤 enum 타입을 사용할지 결정합니다.
- keyUniverse = getKeyUniverse(keyType);
- 위에서 결정된 keyType에 대응하는 enum 상수 배열을 얻습니다.
- vals = new Object[keyUniverse.length];
- keyUniverse.length만큼의 값을 저장할 배열을 만들고 vals에 연결합니다.
- putAll(m);
- m에 들어있는 모든 (키, 값) 매핑을 EnumMap으로 옮겨 담습니다.
- 내부적으로 (enumKey.ordinal)에 맞춰 vals[ordinal]에 값이 들어가며, size도 증가하게 됩니다.
내부 상태 필드 요약
- keyType:
- 만약 m이 이미 EnumMap이면, 그 EnumMap의 keyType을 그대로 사용
- 일반 Map이면, 첫 번째 키의 enum 클래스 타입을 추출해서 사용
- keyUniverse:
- EnumMap일 경우 그 참조를 그대로,
- 일반 Map이면 새로 얻은 enum 상수 배열을 사용
- vals:
- EnumMap이면 복제,
- 일반 Map이면 새로 Object[]를 할당
- size:
- EnumMap에서 왔으면 그대로 복사,
- 일반 Map이면 putAll(m) 과정에서 실제로 (키, 값)을 넣으면서 증가
# 생성자 총 정리
- EnumMap은 생성 시점에 “어떤 enum 타입”을 쓸지 반드시 알아야 하며, 이 정보로부터 enum 상수 목록(keyUniverse)을 만들어 둡니다.
- keyUniverse 크기만큼 vals 배열을 확보해서, (키, 값) 매핑을 인덱스로 직결시키는 구조로 동작합니다.
- 복제 생성자나 Map 기반 생성자는, 내부 EnumMap 로직을 공유 혹은 새로 만들어서 데이터를 이관하는 방식입니다.
결과적으로 각 생성자가 enum 타입 식별 및 배열 초기화 방식을 다르게 처리하지만, 최종적으로는 (enum 상수 배열) + (값 배열) + (size)라는 동일한 구조를 세팅하게 됩니다.
3. 메서드
EnumMap이 사용할 수 있는 메서드는 정말 다양하다. 상속받은 부모의 메서드를 사용할 수 있고, 추상 인터페이스의 default 메서드들도 사용할 수 있기 때문이다.

EnumMap의 고유 메서드는 다음과 같다.

Chapter4. EnumMap이 HashMap보다 빠른 이유
EnumMap이 HashMap보다 빠를 가능성이 큰 이유는 'hash 기반'이 아니라, 'enum 상수 배열 기반'으로 동작한다는 점에 있습니다. 즉, 키가 될 수 있는 enum 상수 개수가 고정되어 있고, 각 상수가 고유 ordinal()을 가지므로, 추가적인 해시 연산 없이 배열 인덱스로 바로 접근이 가능합니다.
1. 해싱(= Hash 연산) 불필요
- HashMap은 키로부터 해시 값을 계산한 뒤, 그 값을 버킷 인덱스로 사용합니다.
- 만약 충돌(collision)이 일어나면 연결 리스트나 트리 구조로 추가 탐색이 필요합니다.
- EnumMap은 "키 enum 상수의 ordinal() → 배열 인덱스"로 직접 연결되므로,
- 해시 충돌 관리를 할 필요가 없고, 해시 분포 역시 신경 쓰지 않아도 됩니다.
- (예: Color.RED.ordinal() == 0이면, 배열의 0번 인덱스에 곧바로 접근)
즉, 충돌로 인한 성능 저하가 없으며, 상수 시간(O(1)) 접근이 보장됩니다.
HashMap 동작 구조

EnumMap 동작 구조

2. 상수 시간(O(1)) 접근이 매우 단순
- 내부적으로 vals[ enumKey.ordinal() ] 처럼 직접 접근하므로,
- 원소 삽입·검색·삭제가 매우 빠르고, 메모리 접근 패턴도 단순해 CPU 캐시 효율이 좋아집니다.
3. 메모리 구조가 압축적(compact)
- HashMap은 내부적으로
- 해시버킷배열해시 버킷 배열 + 연결리스트(혹은트리)연결 리스트(혹은 트리) 등 복합적인 구조를 가집니다.
- 각 노드(Node, Entry)에 key, value, hash, next(또는 트리 자식)가 들어 있어 객체 참조 오버헤드가 크죠.
- EnumMap은 “enum 상수 전체 배열(keyUniverse) + 같은 길이의 값 배열(vals)”로만 구성됩니다.
- enum 상수의 개수가 고정되어 있고,
- 각 상수가 하나의 고유 인덱스(= ordinal)를 갖으므로,
- 별도의 해시 노드를 생성할 필요가 없습니다.
즉, 메모리 사용량이 적고, 필요한 구조체가 단순하므로 캐시 적중률이 높습니다.
주의 사항
- null 키 미지원: EnumMap은 enum 타입만을 키로 받으므로, null을 넣으면 NullPointerException이 발생합니다.
반면 HashMap은 null 키를 하나까지 허용합니다. - 순서 유지: EnumMap은 enum 상수의 선언 순서대로 내부적으로 관리하므로, 정렬된 순서 보장이 필요할 때도 유용합니다.
(HashMap은 해시 구조에 따라 순서가 달라질 수 있음) - enum 상수 변경 시 주의: 새로운 상수 추가나 순서 변경으로 ordinal 값이 달라지면, 직렬화/역직렬화 등에 호환성 문제가 생길 수 있습니다.
# 정리
EnumMap은 해시 연산 자체가 없고, 배열 인덱스(ordinal) 기반으로 (키→값) 매핑을 관리하기 때문에 매우 빠르고 메모리 효율적입니다. HashMap은 어떤 객체든 키로 사용할 수 있는 범용적인 구조지만, 그만큼 충돌 관리와 복잡한 데이터 구조로 인해 오버헤드가 존재합니다. 따라서 “키가 enum 타입이고, 그 개수가 미리 확정적일 때”는 EnumMap을 사용하는 것이 최적의 선택이 될 가능성이 큽니다.

참고자료
https://sabarada.tistory.com/57
https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/EnumMap.html